选自arXiv
作者:Tianyang Shi等
机器之心编译
参与:魔王
角色扮演游戏允许玩家挑选自己喜欢的角色或定制角色外观,但这一过程比较麻烦。那么,如果输入一张照片就可以将角色的脸换成彭于晏、吴彦祖甚至你自己,是不是觉得省了不少事?最近,网易伏羲实验室、密歇根大学、北航和浙大的研究者提出了一种游戏角色自动创建方法,利用 Face-to-Parameter 的转换快速创建游戏角色,用户还可以自行基于模型结果再次进行修改,直到得到自己满意的人物。

论文链接:https://arxiv.org/abs/1909.01064
角色定制系统是角色扮演游戏(RPG)中的重要组成部分,在 RPG 游戏中玩家可以按照自己的偏好(而不是默认模板)来编辑游戏人物的面部外观,比如流行明星或者自己。
最近,来自网易伏羲实验室、密歇根大学、北航和浙大的研究者发表新研究,提出了一种按照输入人脸图像自动创建游戏人物的方法。研究者基于人脸相似性度量和参数搜索机制实现「对人脸图像的艺术加工」,通过在大量具备物理意义的面部参数空间中执行搜索来解决优化问题。
实验结果表明,该方法创建的游戏人物与输入人像无论在整体外观还是局部细节上都实现了高度相似。去年该方法已被用于新游戏开发,现在它已经被玩家使用超 100 万次。
RPG 游戏中标准游戏角色面部创建工作流程的第一步是:配置大量面部参数。然后游戏引擎以用户指定的参数作为输入,生成 3D 人脸。游戏角色定制可以看作是「单目 3D 人脸重建」或「风格迁移」的特例。然而,长期以来,生成图像语义内容和 3D 结构在计算机视觉领域被认为是艰巨的任务。
玩家参与定制角色尽管增加了游戏的趣味性,使得玩家可以捏出各种各样的面孔,但是需要耗费很多时间在定制参数和调试效果上面。另外,在很多角色扮演游戏,特别是网游中,很多希望能够定制自己的面孔、或者采用明星面孔的玩家对于这样的方法不甚满意。
来自网易伏羲实验室等机构的研究者提出一种按照输入人脸图像自动创建游戏人物的方法,如图 1 所示。该方法通过预测一组具备明确物理意义的面部参数,为骨骼驱动模型(bone-driven model)创建 3D 人物形象。该方法中,每一个参数控制每个人脸组件的单个属性,包括位置、方向和缩放。更重要的是,该方法支持用户在创建结果的基础上进行再加工,游戏玩家可以根据自己的需求对游戏人物做进一步的调整和改进。
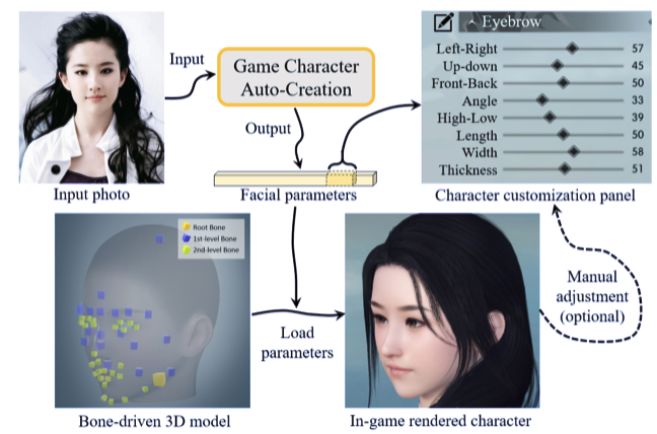
图 1:方法概览。该方法可基于输入人脸图像自动生成游戏角色,它基于人脸相似性度量和参数搜索机制(对大量具备物理意义的面部参数执行搜索)实现。之后用户可以根据需要自行微调生成游戏角色的面部参数。
该研究提出的模型包括模拟器 G(x) 和特征提取器 F (y)。前者模拟游戏引擎的行为,以用户定制的面部参数 x 作为输入,生成「渲染后」的人脸图像 y。后者则决定了人脸相似性度量可以执行的特征空间,以搜索最优的面部参数集。该方法的处理流程图见下图 2:
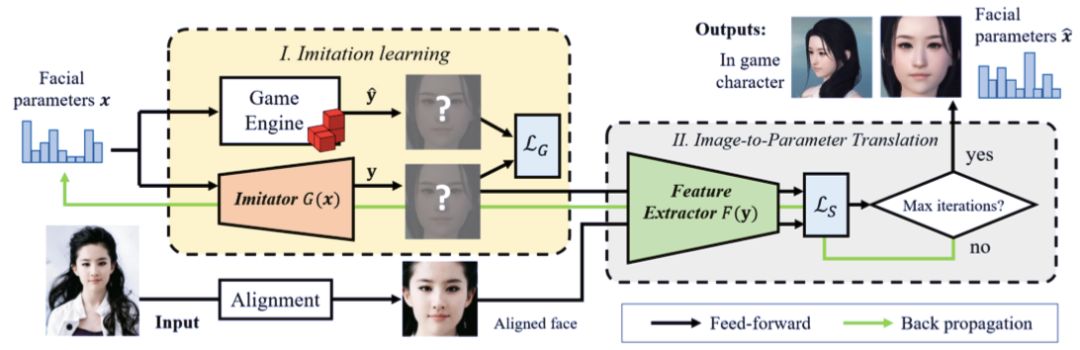
图 2:该方法的处理流程。模型包括模拟器 G(x) 和特征提取器 F (y)。前者模拟游戏引擎的行为,以用户定制的面部参数 x 为输入,生成「渲染后」的人脸图像 y。后者则决定了人脸相似性度量可以执行的特征空间,以搜索最优的面部参数集。
研究者训练了一个卷积神经网络作为模拟器,模拟游戏引擎的输入-输出关系,从而使得角色定制系统可微分。研究者在模拟器 G(x) 中使用了类似 DC-GAN 的网络配置,包括 8 个转置卷积层。出于简洁性的考虑,模拟器仅利用对应的人脸定制参数,拟合人脸模型的前视图。
研究者将模拟器的学习和预测过程构建为基于标准深度学习的回归问题,旨在最小化游戏渲染图像和该方法生成图像在原始像素空间中的差异。
研究者在训练过程中使用了游戏《逆水寒》的引擎,利用对应的人脸定制参数随机生成 20000 个不同人脸。其中 80% 的人脸样本用作训练数据,其余 20% 作为验证数据。
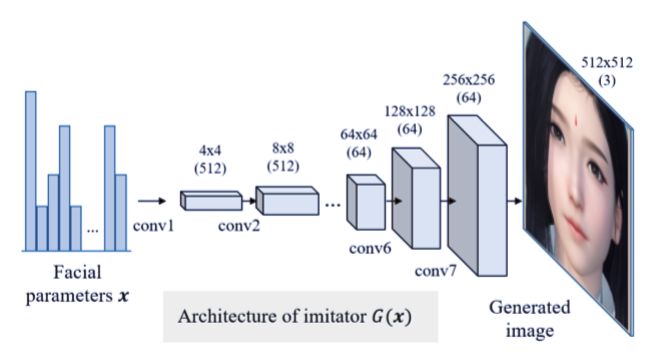
图 3:模拟器 G(x) 的架构。该模拟器的训练目的是,学习从输入人脸定制参数 x 到游戏引擎渲染人脸图像 yˆ 的映射。
模拟器训练完成后,面部参数生成必然成为人脸相似性度量问题。由于输入人脸图像和渲染游戏角色属于不同的图像领域,因此为了高效度量人脸相似性,研究者设计了两种损失函数作为度量指标:人脸整体外观和局部细节。研究者没有直接计算它们在原始像素空间中的损失,而是利用神经风格迁移框架,在神经网络学得的特征空间中计算损失。我们可以把参数生成看作基于模拟器流形的搜索过程,旨在找出最优解,使生成图像和参考图像之间的距离最小化。
图 4:用该研究提出的模拟器 G(x) 及对应的真值所生成的部分人脸图像示例。这些图像的面部参数是手动创建的。
图 5:游戏角色自动创建可以看作是基于模拟器流形的搜索过程,旨在找出 y^∗ = G(x^∗) 的最优解,从而最小化 y 和参考人脸图像 y_r 在特征空间中的距离。
模拟器:卷积核大小设置为 4 × 4,每个转置卷积层的步幅设置为 2,使得特征图的大小在每次卷积后可以翻倍。批归一化和 ReLU 激活函数嵌入在每个卷积层后,输出层除外。使用 SGD 优化器进行训练,批大小设置为 16,动量为 0.9。学习率设置为 0.01,学习率衰减设置为每 50epoch 下降 10%,训练停止设置为 500 个训练 epoch。
人脸分割网络:使用 Resnet-50 作为主干网络(移除其全连接层,在其顶部添加一个 1 × 1 卷积层)。为了提高输出分辨率,研究者将 Conv 3 和 Conv 4 的步幅从 2 更改为 1。该模型在 ImageNet 数据集上执行预训练,然后在 Helen 人脸语义分割数据集上利用像素级交叉熵损失进行微调。模拟器配置同上,不过学习率被设置为 0.001。
面部参数:面部参数的维度 D 被设置为「男性」264、「女性」310。在这些参数中,208 个为连续值(如眉毛长度、宽度和浓密度),其余为离散值(如发型、眉型、胡须类型和唇膏类型)。这些离散参数被编码为 one-hot 向量,并级联为连续向量。由于 one-hot 编码很难优化,因此研究者使用 softmax 函数使离散变量变得平滑。
优化:至于第二阶段中的优化,研究者将 α 设置为 0.01,最大迭代数为 50,学习率 μ 为 10,学习率衰减率为每 5 次迭代减少 20%。
人脸对齐:将输入图像传输到特征提取器之前使用 dlib 库对齐,使用渲染得到的「平均人脸」(average face)图像作为参考数据。
研究者构建了一个名人数据集,包含 50 个人脸特写照片。
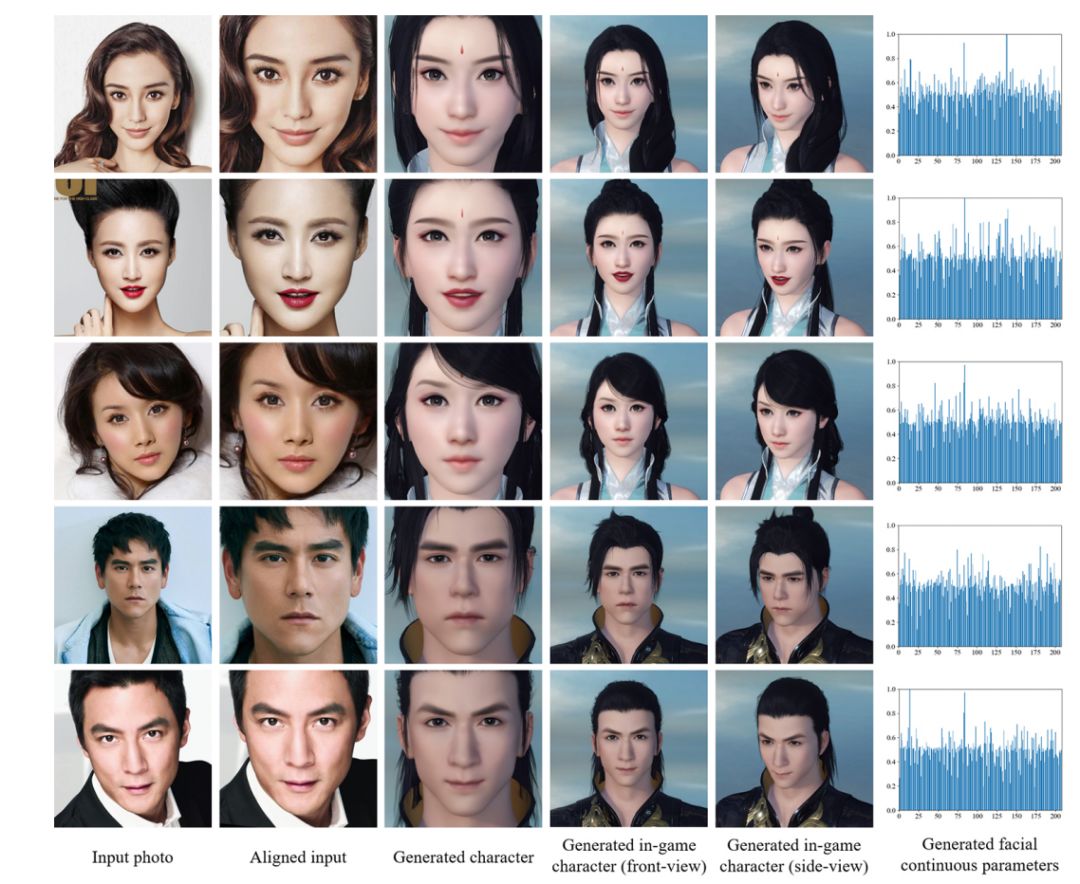
图 7:一些输入图像,及使用该研究提出方法生成的游戏人物(「人物身份」和「表情」均得到建模)。

图 10:与其他 NST 方法的对比。这些方法分别使用每个性别的 Global style [12]、Local style [16],以及「平均人脸」(该研究)作为风格参考。研究者还对比了流行的单目 3D 人脸重建方法:3DMM-CNN。