还记得支付宝「扫鼻子,找狗子」的新功能吗?最近,研究者把论文公布了出来。

世上没有两片完全相同的树叶,也没有完全相同的两个狗 / 猫鼻子。
前段时间,机器之心报道了支付宝上线的一个新功能:利用鼻纹识别帮助养宠物的家庭寻找走失宠物。这一功能的操作非常简单。首先,打开支付宝搜「防走丢」,然后录入宠物鼻纹信息,你就可以为自己的宠物领取一张独一无二的电子「身份证」。一旦宠物走丢,你可以一键报失,如果路人看到走丢宠物,可用支付宝扫鼻纹进行识别,通过虚拟号码联系你,送宠物回家。
这项看似简单的功能其实离不开研究者的悉心钻研,还要克服许多困难,比如宠物鼻子小、纹路不清晰;宠物好动,照片不容易捕捉等。
在最近的一篇 CVPR 2021 论文中,研究者公布了这项功能背后的技术。除了识别猫、狗的鼻纹,这项与细粒度检索任务有关的研究还可以解决其他很多问题。有兴趣的同学可以去阅读原文。

论文链接:https://openaccess.thecvf.com/content/CVPR2021/papers/Xu_Discrimination-Aware_Mechanism_for_Fine-Grained_Representation_Learning_CVPR_2021_paper.pdf
细粒度检索任务是指数据集来自于一个具体的类别,比如狗、猫、人、车、鸟等,需要匹配出具体类别下的个体身份,比如 Person A,Person B。通常采用分类 + 度量学习损失共同监督网络学习,期望得到一个鲁棒的特征提取器,使得提取到的特征在同身份之间的相似度尽可能大,不同身份间的相似性尽可能小,从而能够将与 query 图片同身份的图片检索出来。
这一任务的难点在于:同一个身份由于拍摄的角度、光照、时间等不同而具有较大的差异性。由于细粒度任务的身份同属于一个大类,不同身份间具有较大的相似性,比如同品种的贵宾犬,有相似的体型、外观、毛色,只有一些比较细微的地方具有判别性信息,比如鼻纹纹理、眼睛形状、细微的花纹形状等,因此学到的特征需要能够捕捉到一些细微的有判别性的差异,从而区分图片样本的身份。
现有的方法通常将特征的所有元素作为一个整体来进行监督优化,包括设计更优的损失函数 [1,2],构造注意力机制使网络关注一些重要区域 [3],在训练中随机擦除图片 | 特征元素提升一定的泛化性 [4,5]。这对于细粒度任务来说不是最优的,当特征中的某些元素已经具备区分性时,训练会收敛,从而忽略了继续学习一些具有判别性的细节信息。
本文的目的是学习一种特征,使得特征的每个元素都具有区分性,以此来让特征提取到尽可能多的信息,提升特征整体的区分性,从而能够区分细粒度样本间的身份。为了学习到每个元素都具备区分性的特征,研究者提出了一种判别性感知机制——DAM。通过迭代地将已具备判别性的元素擦除、保留判别性较弱的元素继续学习,不断将特征空间变难,循环优化使得最后得到的特征更为鲁棒。
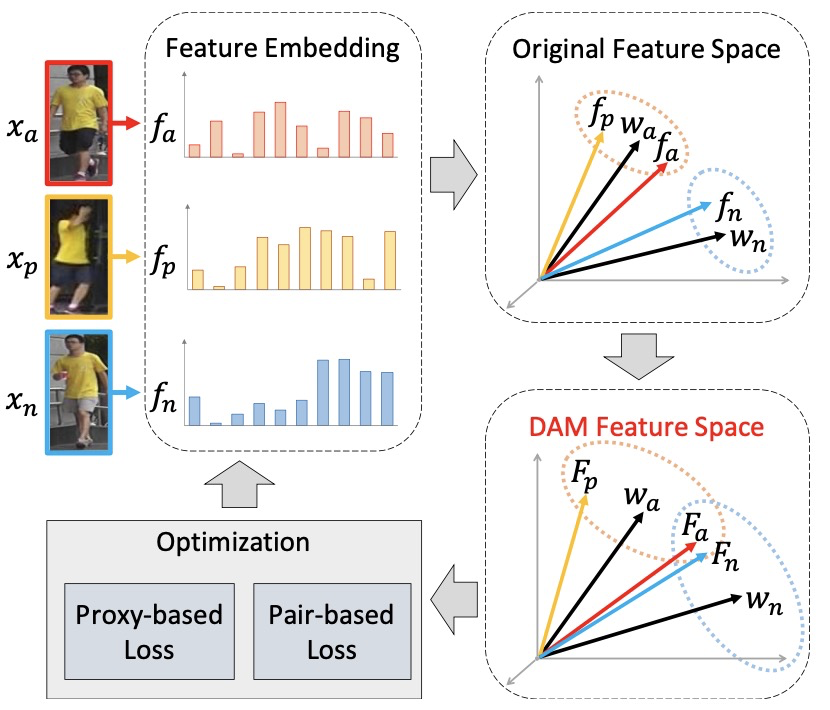
为了确定特征中需要继续学习的元素,首先需要计算每个元素的判别性。对于不同身份的样本,如果特征元素的差异较大,说明该特征元素已具备判别性;反之,该特征元素需要继续学习。因此,采用身份之间的各个特征元素的差异来判别判别性。网络分类器的参数具备特征分类能力,通过利用 cross-entropy 计算特征投影到各个分类器的参数间的相似性来进行优化,因此网络分类器的参数可以用作身份的代理,分类器中不同身份参数的各个元素间的差异可以反映不同身份特征元素间的差异。
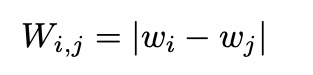
w_i 是一个和特征维度相等的向量,表示身份 i 对应分类器的参数,W_{i,j} 是一个和特征维度相等的向量,表示身份 i 和身份 j 之间的各个特征元素的差异。
得到不同身份样本间的各个特征元素的差异后,在训练过程中需要根据差异大小对特征元素进行擦除或保留。将判别性大的特征元素进行保留,判别性小的元素进行擦除。
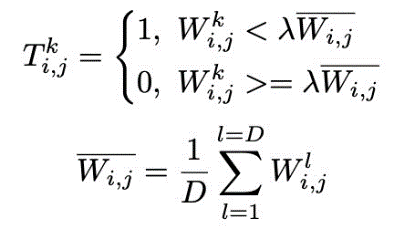
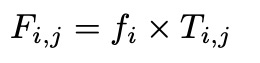
对于同一身份间的不同样本,相互之间具有区分性的特征元素,为对其他所有类别都具备区分性的元素,因此用该身份的分类器参数和其他所有身份分类器参数差异的平均值替代。
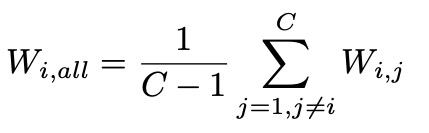
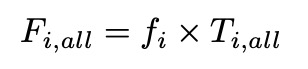
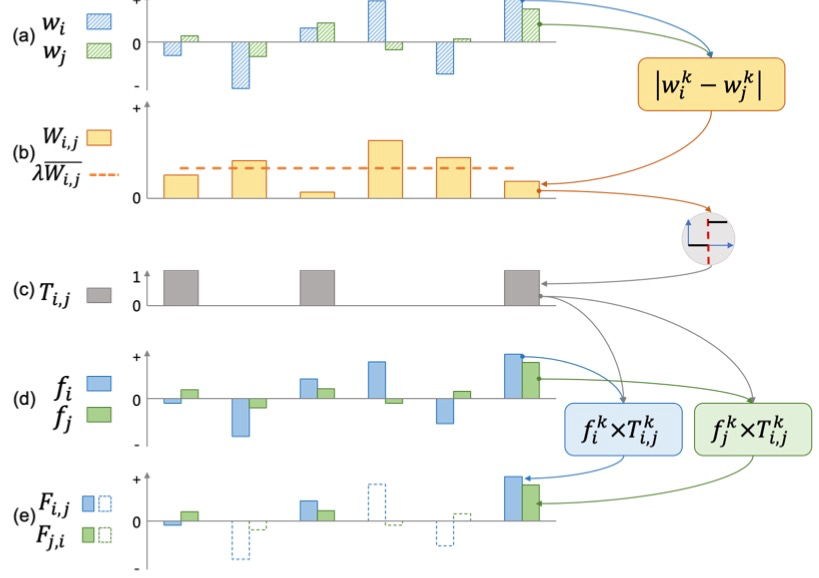
最后对新特征空间中的特征进行分类损失和度量损失监督,不断进行特征优化,从而得到更优的特征。
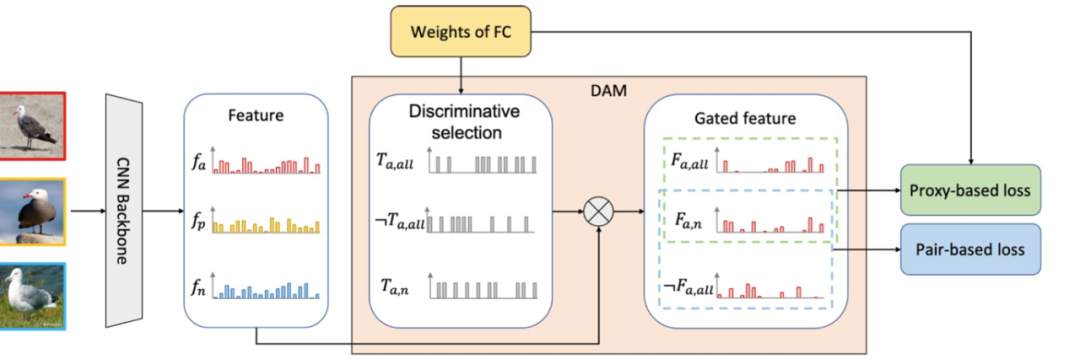
判别性感知机制的效果在多个细粒度检索数据集上进行了验证,包括鸟的数据集 CUB-200-2011,车的数据集 Cars199,行人的数据集 Market-1501、MSMT17。
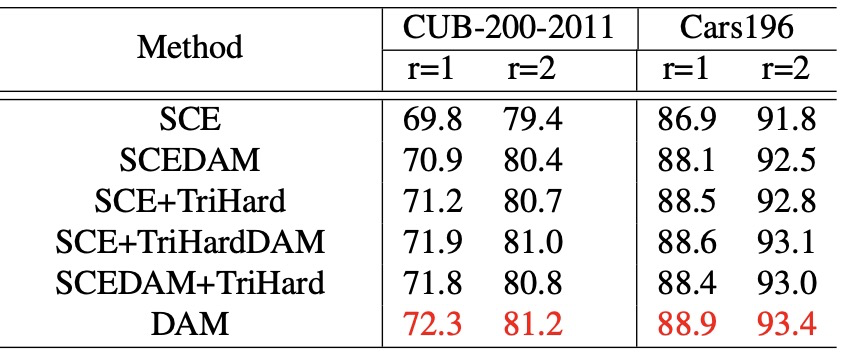
新方法和 state-of-the-art 方法相比也有一定的优越性。
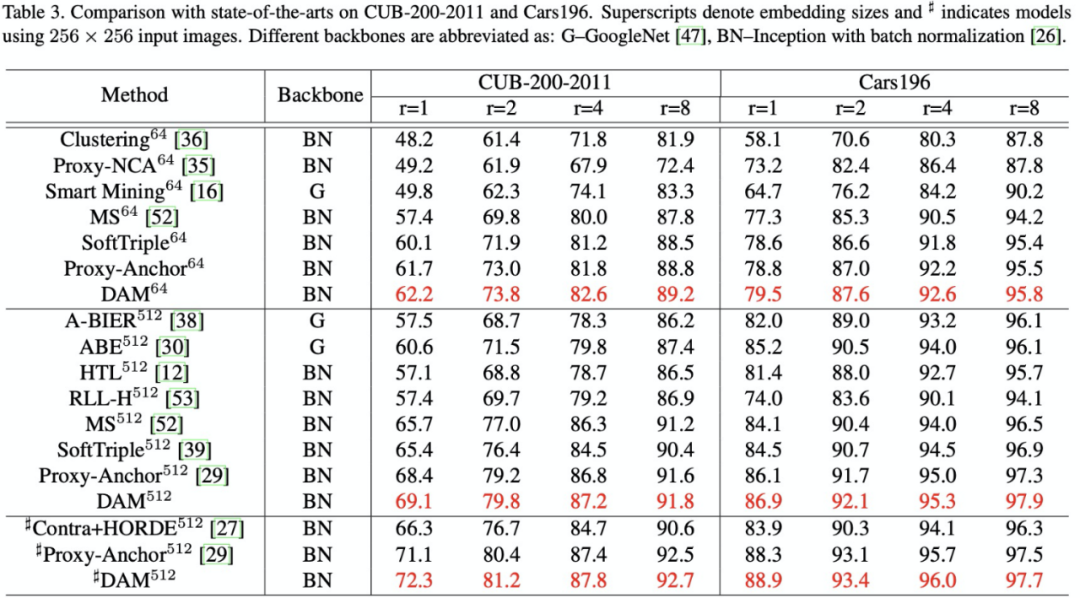
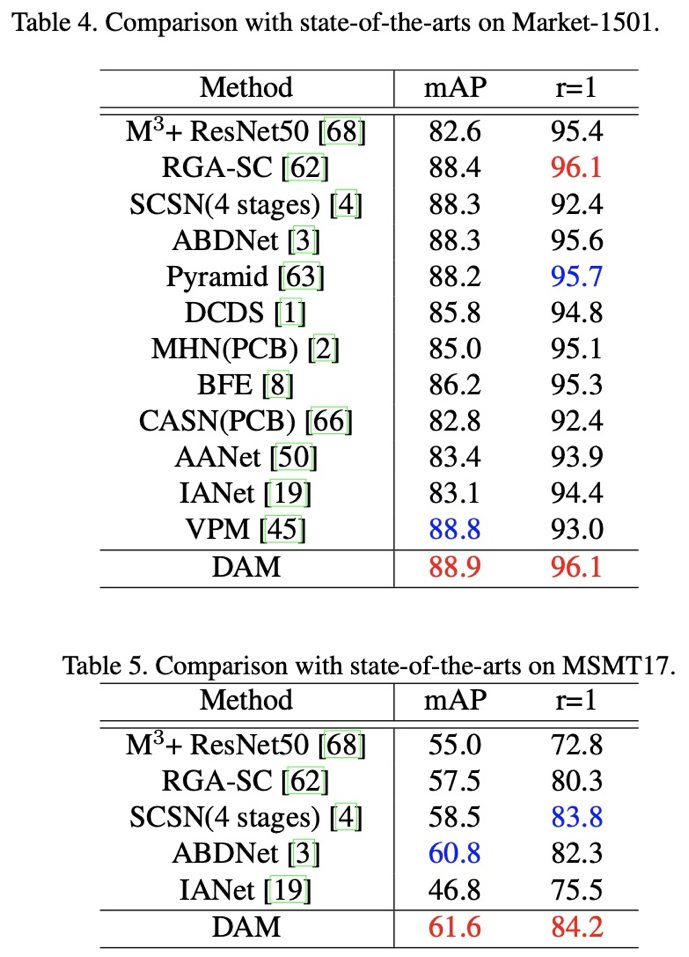
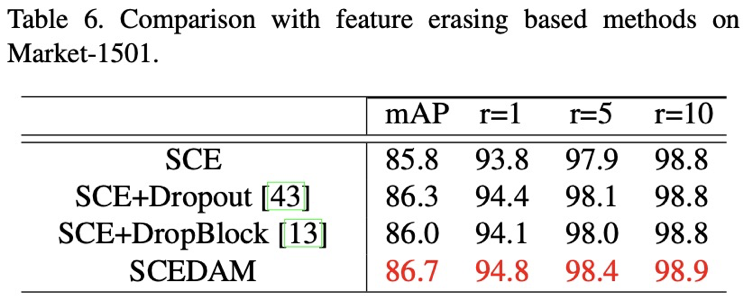
DAM 可以让更多的特征元素具备判别性,这一优势在多个任务上得到了验证,包括公开数据集和宠物场景的 1:1 身份比对、1:N走丢检索、品种识别。在实现的过程中,此方法对于继续学习元素的选择直接采用平均值做取舍,更加动态的选择方法值得进一步探索。
[1] Xun Wang, Xintong Han, Weilin Huang, Dengke Dong, and Matthew R Scott. Multi-similarity loss with general pair weighting for deep metric learning. In CVPR, 2019.
[2] Yifan Sun, Changmao Cheng, Yuhan Zhang, Chi Zhang, Liang Zheng, Zhongdao Wang, and Yichen Wei. Circle loss: A unified perspective of pair similarity optimization. In CVPR, 2020.
[3] Ruibing Hou, Bingpeng Ma, Hong Chang, Xinqian Gu, Shiguang Shan, and Xilin Chen. Interaction-and-aggregation network for person re-identification. In CVPR, 2019.
[4] Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. In AAAI, 2020.
[5] Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V Le. Dropblock: A regularization method for convolutional networks. In NeurIPS, 2018.

机动组是机器之心发起的人工智能技术社区,聚焦于学术研究与技术实践主题内容,为社区用户带来技术线上公开课、学术分享、技术实践、走近顶尖实验室等系列内容。机动组也将不定期举办线下学术交流会与组织人才服务、产业技术对接等活动,欢迎所有 AI 领域技术从业者加入。
-
点击阅读原文,访问机动组官网,观看全部视频内容:
-
关注机动组服务号,获取每周直播预告。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com