英伟达NVL576 Rubin架构代表了AI计算基础设施领域的重大技术突破,作为Blackwell架构的继任者,它不仅在算力规模上实现了质的飞跃,更在系统架构哲学上提出了与传统方法截然不同的创新思路。
一、技术演进与架构哲学
NVL576 Rubin架构是英伟达AI计算战略从芯片级创新向系统级协同的重要转变。作为Blackwell架构的升级版本,NVL576代表了英伟达在AI基础设施领域的”连接两个世界”战略,旨在通过超级芯片和超节点架构,解决日益增长的AI算力需求与摩尔定律放缓之间的矛盾。
从技术演进路径来看,英伟达AI芯片架构经历了从Hopper到Blackwell再到Rubin的代际更迭,每一代都带来了显著的性能提升:
-
Hopper架构:2022年推出,采用台积电4nm制程,单GPU算力约19.5 PFLOPS(FP4) -
Blackwell架构:2024年推出,采用台积电4NP制程,单GPU算力提升至约25 PFLOPS(FP4),NVL72集群可提供约1.1 ExaFLOPS FP4算力 -
Vera Rubin架构:2026年推出,采用台积电N3P制程,单GPU算力达50 PFLOPS(FP4),NVL144集群提供3.6 ExaFLOPS FP4算力 -
Rubin Ultra NVL576架构:2027年推出,单GPU算力提升至100 PFLOPS(FP4),集群规模扩展至576 GPU,提供15 ExaFLOPS FP4推理算力和5 ExaFLOPS FP8训练算力
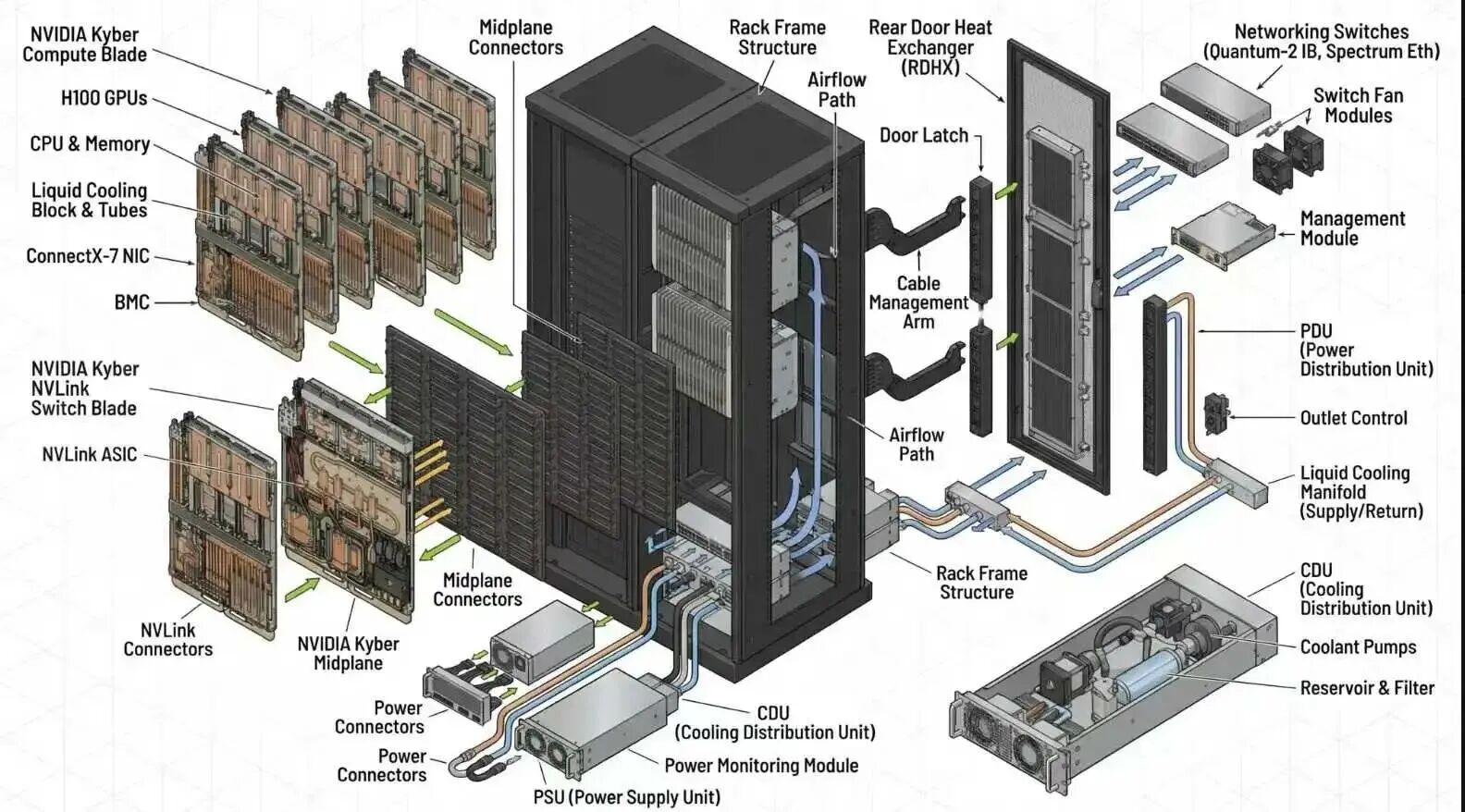
NVL576的设计哲学是”模块化向外扩展”(scale-out within a rack)”与”集群联邦式向外扩展”(scale-out)”相结合的混合架构策略,与华为的”单体超级节点”(monolithic supernode)哲学形成鲜明对比。英伟达选择通过构建高度集成的超级芯片和超节点,实现从单机到机架再到集群的多层次扩展,既保持了计算密度,又确保了系统的可扩展性和灵活性。
二、硬件组成与超级芯片设计
NVL576的核心硬件组成是Vera Rubin超级芯片平台,它由Vera CPU和Rubin GPU两部分构成,通过先进的封装技术和互联技术实现高度集成 。
1. Vera CPU
Vera CPU是英伟达专为AI计算设计的定制化CPU,具有以下关键特性:
-
架构:基于ARM架构,采用88个定制化核心,支持176线程 -
制程:采用台积电N5B制程,优化能效比和散热性能 -
内存:配备32个LPDDR内存插槽,提供高速低延迟内存访问 -
互联:通过NVLink-C2C技术与Rubin GPU实现1.8 TB/s的互联带宽
Vera CPU在超级芯片中扮演着系统控制器和计算协处理器的双重角色,负责任务调度、数据管理以及部分计算负载,与Rubin GPU形成紧密协同的计算单元。
2. Rubin GPU
Rubin GPU是NVL576平台的核心计算单元,具有以下关键特性:
-
架构:基于Vera Rubin架构,采用台积电N3P制程 -
核心配置:每颗GPU由两颗光罩级计算芯片组成,通过SoIC三维垂直堆叠技术与一颗N5B制程的I/O芯片整合 -
显存:支持8层HBM4高带宽内存,单GPU显存容量为288GB,Rubin Ultra版本升级至12层HBM4e,显存容量达1TB -
算力:单GPU FP4推理算力50 PFLOPS,Rubin Ultra版本提升至100 PFLOPS -
互联:通过NVLink 6技术实现3.6 TB/s的带宽,支持与机架内其他GPU的高速互联
Rubin GPU的创新在于其采用的芯粒(Chiplet)设计与3D堆叠封装技术,通过将计算核心、内存控制器和I/O芯片分别优化设计,然后垂直堆叠,显著提升了芯片的集成度和性能。
3.超级芯片封装技术
Vera Rubin超级芯片采用CoWoS-L+SoIC三维堆叠封装技术,实现了CPU与GPU的紧密集成:
-
CoWoS-L封装:台积电的先进封装技术,支持多芯片堆叠,提供高带宽、低延迟的芯片间通信 -
SoIC技术:System-on-Integrated-Circuit,实现计算芯片与I/O芯片的垂直堆叠,优化信号完整性 -
中介层设计:在超级芯片内部,通过硅中介层连接Vera CPU和Rubin GPU,确保高速、低功耗的芯片间通信
这种封装技术使得Vera CPU与Rubin GPU之间可以实现芯片级的直接通信,带宽高达1.8 TB/s,比传统PCIe接口高出25倍,显著降低了数据传输的能源消耗和延迟 。
三、互联方案与拓扑结构
NVL576的互联方案是其最大的技术亮点,它采用多层次、多协议的互联架构,从芯片级到机架级再到集群级,实现了全方位的高效数据传输。
1. NVLink-C2C芯片级互联
NVLink-C2C是英伟达为Vera Rubin超级芯片设计的芯片级互联技术:
-
带宽:1.8 TB/s,支持CPU与GPU之间的直接通信 -
延迟:低于1μs,实现近乎零延迟的芯片间通信 -
协议:支持一致性内存访问(Cache-Coherent),形成统一的内存模型 -
优势:相比PCIe Gen5,能源效率提高25倍,面积节省90倍
NVLink-C2C技术使Vera CPU和Rubin GPU能够像单一实体般协同工作,为AI训练和推理提供了高效的计算资源池。
2. NVLink 6机架级互联
NVL576平台采用NVLink 6技术实现机架内GPU的互联:
-
带宽:3.6 TB/s(单端口),支持全互联拓扑 -
延迟:低于1μs,确保大规模分布式训练的低延迟通信 -
拓扑结构:采用3D torus结构,实现GPU间的低延迟、高带宽互联 -
连接器:每个计算刀片配备18列4行的连接器,支持与机架内其他刀片的直接连接
NVL576平台通过NVLink 6技术,实现了576颗GPU在同一机架内的全互联,为超大规模AI模型训练提供了基础 。
3. CPO光电共封装技术
为解决大规模集群互联的带宽瓶颈,NVL576采用了光电共封装(CPO)技术:
-
部署层级:主要用于机柜间互联,光模块数量为GPU的9倍 -
带宽:单端口1.6 Tbps,支持长距离、低延迟的光信号传输 -
优势:相比传统铜缆,CPO技术可将带宽提升3.5倍,同时降低能耗
NVL576的互联方案实现了从芯片到机架再到集群的多层次优化,通过NVLink-C2C解决芯片级通信瓶颈,通过NVLink 6实现机架内高密度互联,通过CPO技术支持大规模集群扩展,为超大规模AI计算提供了完整的解决方案。
4. Kyber中板设计
NVL576采用了革命性的Kyber中板设计,替代了传统的电缆盒:
-
设计特点:18列4行的连接器布局,支持高密度计算刀片互联 -
优势:移除风扇和电源,增加计算密度;无需考虑气流切口,提高空间利用率 -
散热支持:配合微通道冷板液冷系统,解决2300W TDP的散热挑战 -
规模扩展:支持16机柜互联,构建超大规模AI集群
Kyber中板设计是NVL576实现高密度计算的关键创新,它不仅提高了空间利用率,还简化了系统部署,使得NVL576能够实现576颗GPU/机架的超高密度配置。
四、性能指标与计算能力
NVL576作为英伟达最新的AI计算平台,在性能指标上实现了质的飞跃:
1. 算力性能
-
FP4推理算力:15 ExaFLOPS(机架级),较Blackwell Ultra的GB300 NVL72提升14倍 -
FP8训练算力:5 ExaFLOPS(机架级),较Blackwell Ultra提升约14倍 -
单GPU性能:Rubin GPU提供50 PFLOPS FP4算力,Rubin Ultra版本提升至100 PFLOPS -
集群扩展:通过16机柜互联,可构建超大规模AI集群,支持数百万颗GPU协同工作
这些性能指标表明,NVL576在单机架算力密度上实现了巨大突破,为超大规模AI模型训练提供了硬件基础。
2. 内存与带宽性能
-
HBM4显存带宽:4.6 PB/s(机架级),较Blackwell Ultra的10TB/s提升460倍 -
快速存储容量:365 TB(机架级),较Blackwell Ultra的75TB提升近5倍 -
NVLink集群带宽:260 TB/s(NVL144平台),较Blackwell Ultra提升约3.3倍 -
CX9网络带宽:28.8 TB/s,支持高速网络通信
NVL576的内存带宽性能提升尤为显著,通过HBM4e显存和NVLink 6互联技术,解决了AI计算中的内存墙问题,为超大规模模型提供了充足的带宽支持。
3. 功耗与散热
-
单GPU TDP:2300W,较Blackwell Ultra的1800W有所提升 -
散热方案:采用微通道冷板液冷系统,解决高密度计算的散热挑战 -
机架功耗:单机架功率最高可达120千瓦,支持高密度部署 -
冷却效率:液冷系统能效比风冷系统提高30%以上,适合大规模AI计算中心
NVL576的高功耗设计虽然带来了散热挑战,但也体现了英伟达对算力密度最大化的追求,通过先进的液冷技术,确保了系统的稳定运行。
五、应用场景与工作负载优化
NVL576的设计充分考虑了未来AI工作负载的需求,针对多种应用场景进行了专门优化:
1. 超长上下文推理
-
采用稀疏张量编码和量化存储技术,减少内存占用 -
通过Vera CPU的Arm核心集群管理跨GPU的KV缓存分片 -
支持动态精度调整,根据上下文长度自动选择最佳精度
超长上下文推理是NVL576的核心应用场景之一,通过系统级优化,解决了大模型推理中的内存和带宽瓶颈问题。
2. 高分辨率视频生成
-
采用分块渲染技术,将视频分割为多区域并行处理 -
集成专用编解码引擎(NVENC/NVDEC),支持多模态AI应用 -
利用高带宽HBM4e显存存储中间帧数据,通过光流算法优化运动估计
NVL576在视频生成方面的优化,使其成为AI内容生产的理想平台,能够处理高分辨率、长时序的视频生成任务。
3. 万亿参数模型训练
-
采用动态精度调整(FP8/FP16混合)减少通信开销 -
通过梯度压缩算法优化分布式训练中的数据传输 -
支持模型并行和数据并行的混合训练策略
NVL576在超大规模模型训练方面具有显著优势,通过多层次互联和优化算法,实现了超大规模模型训练的高效并行。
4. 液冷与高密度部署
-
采用浸没式液冷模块,提高散热效率 -
高阶PCB设计,支持高密度计算单元部署 -
液冷AI服务器机架设计,1吉瓦数据中心需8000个此类机架
NVL576的液冷和高密度部署方案,是其面向大规模AI算力中心的重要优化,降低了部署成本和时间。
六、市场定位与竞争分析
1. 市场定位
NVL576的市场定位明确为超大规模AI计算基础设施,主要面向以下场景:
-
国家级AI超算:如美国能源部与英伟达合作的项目,为科学研究和国家安全提供算力支持 -
云服务商:微软、谷歌等大型云厂商,用于构建AI训练和推理服务 -
自动驾驶:高精度自动驾驶模型的训练和仿真 -
科研机构:高校和研究机构的超大规模AI研究项目
NVL576的市场定位是英伟达”AI工厂”战略的核心组成部分,旨在将AI训练和推理过程标准化、工厂化,使AI模型能像流水线产品一样快速训练和部署。
2. 竞争分析
NVL576面临的主要竞争对手是华为的CloudMatrix 384架构,两者代表了两种不同的AI基础设施设计理念:
|
参数 |
NVL576 Rubin Ultra |
华为CloudMatrix 384 |
|
GPU数量/机架 |
576颗 |
384颗 |
|
FP4算力/机架 |
15 ExaFLOPS |
300 PFLOPS (FP16) |
|
内存带宽 |
4.6 PB/s (HBM4e) |
2.8 TB/s (全对等互联) |
|
算力利用率 |
较高 |
提升30% |
|
部署范围 |
全球化部署 |
中国及周边地区 |
NVL576与华为CloudMatrix 384的核心竞争在于架构哲学:英伟达坚持芯片级、计算优先的主导地位,通过模块化的机柜级”向上扩展”(scale-up within a rack)与集群联邦式”向外扩展”(scale-out)战略延伸其统治力;而华为则奉行系统级、通信优先的单体超级节点(monomorphic supernode)哲学,通过构建庞大、扁平化的通信域来弥补单个芯片性能短板的”向上扩展”(scale-up)方法 。
在实际应用中,NVL576凭借更高的单机架算力密度和更灵活的扩展能力,在超大规模模型训练方面具有显著优势;而华为CloudMatrix 384则在局部高密度通信和资源利用率方面表现突出,适合特定场景的高效计算。
3. 英伟达AI基础设施战略
NVL576是英伟达AI基础设施战略的重要组成部分,其战略核心包括:
-
三芯战略:CPU、GPU、DPU的协同设计,构建统一架构AI芯片产品 -
全球化与本地化平衡:通过欧洲AI工厂和中东合作分散市场风险,适应地缘政治变化 -
生态绑定:CUDA和Dynamo平台形成开发者壁垒,迫使云厂商和AI公司依赖其基础设施 -
标准化AI基础设施:推出基于MGX架构的模块化快速建造算力中心,支持液冷技术与高密度部署
英伟达的AI基础设施战略旨在构建”算力底座+生态闭环+多领域渗透”的全链条优势,通过核心技术迭代、生态构建与国家算力竞争,巩固其在全球AI硬件市场的主导地位。
七、总结
NVL576 Rubin架构代表了英伟达在AI计算基础设施领域的重大突破,通过超级芯片设计、多层次互联架构和液冷高密度部署,实现了超大规模AI计算的硬件基础。
NVL576的创新不仅在于其性能指标,更在于其架构哲学的转变。从芯片级创新向系统级协同,从单一计算单元向超节点集群,英伟达正在重新定义AI计算基础设施的标准。通过NVLink-C2C芯片级互联、NVLink 6机架级互联和CPO光电共封装技术,NVL576构建了一个从芯片到集群的全方位高效通信网络,为超大规模AI模型提供了理想的计算环境。
展望未来,NVL576的部署将推动全球AI算力市场的二元化发展,一方面英伟达通过其技术优势和生态绑定继续主导高端市场,另一方面华为等中国厂商通过系统级创新在特定领域形成竞争力。这种二元化格局将促进全球AI硬件技术的多元化发展,为不同应用场景提供更丰富的选择。
随着AI技术的持续发展和模型规模的不断增长,NVL576及其后续版本将继续引领AI基础设施的技术创新,推动全球AI产业进入新的发展阶段。