William Faulker:「过去永远不会死,它甚至还没有过去。」
CISC 和 RISC 是 David Patterson 和 David Ditzel 在 1981 年正式提出的。四十年过去了,二者的发展有哪些融合与变迁?IT 新闻界资深人士 Joel Hruska 撰长文对该领域的发展史及其将面临的挑战做了详细阐述,以下是文章原文。
随着基于 ARM 的 M1 被推出,关于 x86 和 ARM 的比较和讨论也越来越多。这些讨论通常还涉及 CISC 和 RISC,因为「x86 与 ARM」和「CISC 与 RISC」之间的非常紧密。
但这种关联造成了一种误解:「x86 与 ARM 可以被对应归类为 CISC 与 RISC,其中 x86 是 CISC,ARM 是 RISC」,三十年前的确是这样,但现在已经不是了。
人们经常将 x86 CPU 与其他公司制造的处理器进行比较,但近二十年来 x86 都没有一个真正的架构竞争对手。

RISC 是 David Patterson 和 David Ditzel 在他们 1981 年的开创性论文《The Case for a Reduced Instruction Set Computer》中创造的术语。他们根据 20 世纪 70 年代后期领域内的发展趋势以及当时 CPU 面临的扩展问题,正式提出了 RISC 这种半导体设计方法。此外,他们还提出了另一个术语「CISC(复杂指令集)」,来描述许多已经存在但不遵循 RISC 原则的 CPU 架构。
随着限制 CPU 性能的瓶颈发生改变,人们意识到需要一种新的 CPU 设计方法。原始 8086 就是遵循 CISC 设计原则的一个例子,它旨在通过将复杂性转移到硬件中,来缓解内存成本高的问题。这种方法强调代码密度和对一个变量依次执行多个操作的某些指令。作为一种设计理念,CISC 试图最小化 CPU 执行给定任务所必需的指令数来提高性能,其指令集架构通常会提供一些专用指令。
20 世纪 70 年代后期,CISC CPU 存在很多缺点。它们通常必须跨多个芯片才能实现,因为当时的超大规模集成电路(VLSI)技术无法将所有必要的组件封装到一起。实现支持大量极少用指令的复杂指令集架构需要消耗 die space,并且可实现的最大时钟速度也有限。与此同时,内存成本持续降低,代码尺寸变得不那么重要了。
Patterson 和 Ditzel 认为当时 CISC CPU 仍在尝试解决代码膨胀问题,他们意识到绝大多数 CISC 指令都没有被用到。因此他们提出了一种完全不同的处理器设计方法——一个小得多的指令集 RISC,其中的指令长度固定,并且所有指令都能在单个时钟周期内完成。尽管 RISC CPU 每条指令执行的工作量比 CISC 的对应指令少了一些,但芯片设计人员通过简化处理器来弥补了这一点。
这种简化允许把晶体管的预算用来实现其他功能,例如用于一些额外的寄存器。1981 年人们设想未来可用的功能包括片上缓存、更大更快的晶体管,甚至是 pipelining 技术。RISC CPU 的目标是尽可能加快指令执行速度,提高 IPC(即每个时钟周期内执行的指令数,用于度量 CPU 的效率)。Patterson 和 Ditzel 认为,通过以这种方式重新分配资源,RISC 的性能最终将优于 CISC。
不久这种猜想就被证实。MIPS 于 1985 年推出的 R2000 在某些情况下能够维持接近 1 的 IPC。早期的 RISC CPU,例如 SPARC 和 HP 的 PA-RISC 系列,都创造了性能记录。在 20 世纪 80 年代末和 90 年代初,人们常说:「x86 等基于 CISC 的架构已经过时了,也许对于家庭计算来说足够了,但如果您想使用真正的 CPU,请购买 RISC 芯片」。以数据中心、工作站和高性能计算 (HPC) 为例:
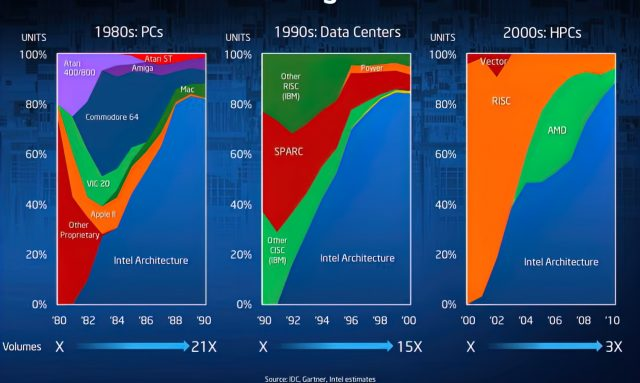
注:此处「英特尔架构」仅指 x86 CPU,而不是 8080 等芯片,后者在早期的计算机市场上很受欢迎。此外,英特尔在 2000 年拥有许多属于「RISC」类的超级计算机,并且 x86 机器在市场上还占据较大的份额。
上图分析了 80 年代 – 00 年代 CPU 的市场状况。截止到 1990 年,在个人计算机市场,x86 占据了相当大的市场份额,非 x86 CPU 仅占约 20%;但在数据中心方面,x86 几乎没有份额,在 HPC 中也没有。当时苹果正准备设计下一代 CPU,1991 年苹果、IBM、Motorola 组成的 AIM 联盟推出了微处理器架构 PowerPC,他们相信按照 RISC 原则构建的高性能 CPU 将是计算机的未来。
CISC 与 RISC 并肩发展的历史至 20 世纪 90 年代初为止。英特尔的 x86 架构在 PC、数据中心和 HPC 等计算行业继续占据主导地位的事实是无可争议的,有争议的是:英特尔和 AMD 的 CPU 架构是否真的是采用 RISC 设计原则实现的
在 CPU 开发领域,一些概念和属性是长期存在分歧的。例如 Paul DeMone 曾在《RISC vs. CISC Still Matters》一文中写道:
随着使用固定长度控制字来操纵乱序执行数据路径的现代 x86 处理器的出现,RISC 和 CISC 之间的混淆变得越来越严重。「RISC 和 CISC 正在融合」是一个在根本上就存在缺陷的观点,可以追溯到 1992 年 i486 的发布。其根源在于人们对指令集架构和物理处理器实现细节之间的差异普遍无知。
相比之下,Jon Stokes 在《RISC vs. CISC: the Post-RISC Era》中说:
显然到目前为止,「RISC」和「CISC」这两种缩写术语掩盖了一个事实,即两种设计理念都不仅仅处理指令集的简单性或复杂性…… 从 RISC 和 CISC 的发展史以及两种方法试图解决的问题看,这两个术语都很荒谬…… 关于「RISC 与 CISC」的辩论早已结束,现在必须要进行一个更细致入微、更有趣的讨论,即基于硬件和软件、ISA 和实现等方面进行讨论。
然而,这些文章都过时了。Stokes 的文章写于 1999 年,DeMone 的文章写于 2000 年。这里引用他们的文章是为了说明 RISC 与 CISC 和现代计算的关联早已有 20 多年的历史。
上文提到的引述反映了关于「CISC 与 RISC」的两种不同观点。DeMone 的观点与今天 ARM 和苹果的观点基本一致,这种观点被称为「以 ISA 为中心(ISA-centric position)」。
在过去几十年里,Stokes 的观点是 PC 领域的主流观点,被称为「以实现为中心(implementation-centric position)」。我使用「实现(implementation)」这个词是因为它可以在上下文中指代 CPU 的微架构或用于制造物理芯片的制程节点。
上述两种位置都以「中心(centric)」的形式描述,两种观点之间是存在交集的。即使观点不一,但都遵循一些共同的趋势。
在以 ISA 为中心的观点中,RISC 指令集的某些先天特征使其比 x86 更高效,包括使用固定长度指令和加载 / 存储设计。虽然 CISC 和 RISC 之间的一些原始差异不再有意义,但以 ISA 为中心的观点认为,就 x86 和 ARM 之间的性能和能效而言,仍然具有一些关键差异。
以 ISA 为中心的观点认为,英特尔、AMD 和 x86 胜过 MIPS、SPARC 和 POWER/PowerPC,原因有以下三个:英特尔卓越的工艺制造、英特尔的优势使所谓的「CISC tax」逐渐减少、二进制兼容性提升了 x86 的价值。
以实现为中心的观点则着眼于自 RISC、CISC 等术语出现以来现代 CPU 的发展方式,并认为这两种术语已完全过时。
例如,现在 x86 和高端 ARM CPU 都使用乱序执行来提高 CPU 的性能。而使用芯片即时重排序指令以提高执行效率的做法与 RISC 的原始设计理念完全不一致,Patterson 和 Ditzel 主张采用能够以更高时钟速度运行的不太复杂的 CPU。现代 ARM CPU 还有一些特性,例如 SIMD 执行单元和分支预测,在 1981 年也都不存在。RISC 最初的目标是让所有指令都能在一个周期内执行,大多数 ARM 指令都符合这个规则,但是 ARMv8 ISA 和 ARMv9 ISA 包含执行时间超过一个时钟周期的指令。现代 x86 CPU 也是如此。
以实现为中心的观点认为:制程节点改进和微架构增强的结合使 x86 在很久以前就可以缩小与 RISC CPU 的差距,并且 ISA 级别的差异在非常低的功率范围内无关紧要。英特尔和 AMD 等都普遍支持这种观点,2014 年我曾撰写一篇题为《The final ISA showdown: Is ARM, x86, or MIPS intrinsically more power efficient?》的相关文章。
2014 年文章链接:https://www.extremetech.com/extreme/188396-the-final-isa-showdown-is-arm-x86-or-mips-intrinsically-more-power-efficient
以实现为中心的观点认为,CISC 和 RISC CPU 已经交互发展了几十年,从 1990 年代中期为 x86 CPU 采用「类 RISC」解码方法开始。
常见的解释是这样的:在 1990 年代初期,英特尔和其他 x86 CPU 制造商意识到未来提高 CPU 性能需要的不仅仅是更大的缓存和更快的时钟。多家公司决定投资 x86 CPU 微架构,以动态重排序他们自己的指令流来提高性能。在该过程中,原生 x86 指令被送入 x86 解码器,并在执行前转换为「类 RISC」微操作。
二十多年来业界的观点一直是如此,但最近这种观点遭到了挑战。2020 年 Erik Engheim 写道:「x86 芯片中根本没有 RISC 的内部结构,这只是一种营销策略。」他还提到了 DeMone 的故事和 P6 微架构背后的首席架构师 Bob Colwell 的一句话。
P6 微架构是第一个实现乱序执行和原生 x86 到微操作解码引擎的英特尔微架构。P6 随奔腾 Pro 发布,后来又演变出奔腾 II、奔腾 3 及更高版本。它是现代 x86 CPU 的鼻祖。因此,P6 微架构的首席架构师 Bob Colwell 有资格解释上文所述的挑战,他说:
英特尔的 x86 在「引擎的外表」下并没有 RISC 引擎。它们通过依赖于将 x86 指令映射到机器操作或复杂指令的机器操作序列的解码 / 执行的方案来实现 x86 指令集架构,然后这些操作通过微架构找到自己的方式,遵守有关数据依赖的各种规则,最终确定时序。
完成这个过程的「微操作」有 100 多比特,携带各种复杂特异的信息,不能由编译器直接生成,且不一定是单周期。但最重要的是,它们只是一种微架构技巧,而 RISC/CISC 是关于指令集架构的。微操作的想法不是受 RISC 启发的、「类 RISC」的,或者说与 RISC 完全无关。而是我们的设计团队找到了一种方法,打破了非常复杂的指令集的复杂性,也摆脱了竞争型微处理器中存在的限制。
英特尔并不是首个将 x86 前端解码器与所谓的 RISC 风格后端结合起来的 x86 CPU 制造商,被 AMD 收购的 NexGen 同样如此。NexGen 5×86 CPU 于 1994 年 3 月首次亮相,而奔腾 Pro 直到 1995 年 11 月才推出。以下是 NexGen 对其 CPU 的描述:Nx586 处理器是 NexGen 创新以及 RISC86 微架构专利的首次实现。后来该公司给出了更多实现细节:RISC86 方法动态地将 x86 指令转化为 RISC86 指令。如下图所示,Nx586 利用了 RISC 性能原理的优势。出于 RISC86 环境的限制,每个执行单元都要更小更紧凑。
也许人们依然觉得这只是市场营销的说辞,那么让我们再来看下 1996 年的 AMD K5。K5 通常被描述为与 AMD 从其 32 位 RISC 微控制器 Am29000 借来的执行后端结和的 x86 前端。在查看它的具体框架图之前,我们首先把它与最初的英特尔奔腾比较一下。奔腾可以说是 CISC x86 进化的顶峰,因为它在 x86 CPU 中同时实现了 pipeline 和超标量设计(superscaling),但没有将 x86 指令转换为微操作,也缺乏乱序执行引擎。

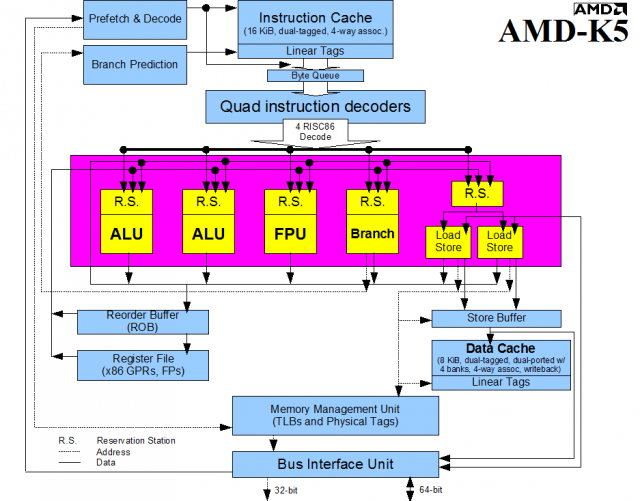
如果你曾经研究过微处理器原理图,你可能会发现 K5 和微处理器有许多相似之处,但奔腾却相反。AMD 在 Nx586 上市后收购了 NexGen。K5 是 AMD 自主设计的,而 K6 最初是 NexGen 的产品。也是从那时开始,CPU 变得像今天我们熟悉的样子。设计这些芯片的工程师曾表示:这些相似之处不仅仅是表面上的。
早在 1996 年,AMD 的 David Christie 就在 IEEE Micro 上发表了一篇关于 K5 的文章,阐述了 K5 是如何将 RISC 和 CISC 结合在一起的,这里引用一段该文章的内容:
我们开发了一个松散地基于 29000 指令集的微型 ISA。一些额外的控制字段将微指令的大小扩展到 59 位。其中一些简化并加速了超标量控制逻辑,其他的用于提供特定于 x86 的功能,这些功能对于性能非常重要,因此不能用微指令序列来合成。但是这些微指令仍然遵循基本的 RISC 原则:简单的寄存器到寄存器操作,对寄存器指定符和其他字段进行固定位置编码,并且每个操作不多于一个内存引用。因此我们称它们为 RISC 操作,或简称为 ROPs。这种简单、通用的特性为实现更复杂的 x86 操作提供了灵活性,从而有利于保持执行逻辑相对简单。
RISC 微架构最关键的一点是 x86 指令集的复杂性止于解码器,并且在很大程度上对乱序执行内核是透明的。这种方法只需要很少的额外控制复杂度,而不需要乱序的 RISC 执行来实现乱序的 x86 执行。任务切换的 ROP 序列看起来并不比简单指令串的 ROP 序列复杂。执行内核的复杂性被有效地从架构的复杂性中分离出来,而不是复合起来的。
Christie 并没有混淆 ISA 与 CPU 物理实现细节之间的区别。他认为物理实现本身在一些重要的方面是 RISC 式的。K5 重用了 AMD 为其 Am29000 系列 RISC CPU 开发的执行后端部分,它实现了一个比原生 x86 ISA 更类似于 RISC 的内部指令集。在此期间,NexGen 和 AMD 引用的 RISC 式技术参考了数据缓存、pipeline 和超标量架构等参考概念。
这些想法都不是严格的 RISC,但它们都是首先在 RISC CPU 中首次亮相的,将这些功能作为「类 RISC」进行营销是有道理的。
这些功能与 RISC 的相关程度以及 x86 CPU 是否解码 RISC 样式指令,取决于选择的框架标准。这一争论比奔腾 Pro 还大,即使 P6 是与乱序执行引擎等技术发展最相关的微架构。不同公司的工程师都有自己的看法。
那么这种「RISC 与 CISC」比较对今天的 ARM 和 x86 CPU 有什么实际影响呢?当我们将 AMD 和英特尔 CPU 与苹果的 M1 和未来的 M2 进行比较时,我们真正要问的问题是:x86 是否存在一些瓶颈,使得其无法与苹果以及高通等公司未来的 ARM 芯片有效竞争?
AMD 和英特尔给出的答案是否定的,而 ARM 给出的答案是肯定的。行业内的公司之间具有明显的利益冲突,因此我询问了丹麦计算机科学家 Agner Fog,他以其在 x86 架构和微架构方面的研究而闻名。以下是他的看法
ISA 并非无关紧要。x86 ISA 非常复杂,因为长期以来人们一直在进行小的更改和补丁,以向 ISA 中添加更多功能,而 ISA 确实已没有空间容纳此类新功能。
复杂的 x86 ISA 使解码成为瓶颈。x86 指令的长度在 1 到 15 个字节之间,计算长度非常复杂。在开始解码下一条指令之前需要知道指令的长度。如果您想每个时钟周期解码 4 或 6 条指令,这肯定是个问题!英特尔和 AMD 现在都在不断增加微操作缓存来克服这个瓶颈。而 ARM 有固定大小的指令,所以这个瓶颈不存在,也不需要微操作缓存。
x86 的另一个问题是它需要很长的管道来处理复杂性。分支误预测惩罚等于 pipeline 的长度。因此,他们正在添加越来越复杂的分支预测机制,其中包含大型分支历史信息表和分支目标缓冲区。当然,所有这些都需要更多的芯片空间和更多的功耗。
尽管有这些负担,x86 ISA 还是相当成功的。这是因为它可以为每条指令做更多的工作。
Agner 还在他的微架构手册中写道:AMD 和英特尔 CPU 设计的最新趋势已经回归到 CISC 原则,以更好地利用有限的代码缓存,增加管道带宽,并通过在 pipeline 中维持较少的微操作数量来降低功耗。这些改进代表了提高 x86 整体性能和功耗效率的微架构变迁。
那么就存在一个重要的问题:现代 AMD 和英特尔 CPU 为 x86 兼容性付出了多大的代价?
Agner 提到的解码瓶颈、分支预测和 pipeline 复杂性是 ARM 认为 x86 产生的「CISC tax」的一部分。过去,英特尔和 AMD 告诉我们解码功耗只是芯片总功耗的极小一部分。但是,如果 CPU 正在为微操作缓存或复杂的分支预测器消耗能量以弥补解码带宽的不足,那么意义就不一样了。微操作缓存功耗和分支预测功耗均由 CPU 的微架构及其制造制程节点决定。「RISC 与 CISC」并没有充分体现这三个变量之间关系的复杂性。
也许我们还需要几年的时间才能知道苹果的 M1 和高通未来的 CPU 是否代表了市场翻天覆地的变化,AMD 和英特尔是否将面临下一个挑战。保持 x86 兼容性是否是现代 CPU 的负担,这既是一个新问题,也是一个非常古老的问题。之所以说它是一个新问题是因为在 M1 推出之前,无法进行有意义的比较;说它是一个旧问题是因为当初 x86 CPU 诞生时,一些个人计算机延续使用非 x86 CPU 就让这个主题引起过相当多的讨论。
AMD 仍在以每年 1.15 至 1.2 倍的速度改进 Zen,英特尔的 Alder Lake 也将使用低功耗 x86 CPU 内核来改进功耗,两家 x86 制造商都在不断改进他们的方法。需要一些时间来观察这些内核及其后继者如何与未来的苹果产品竞争,但 x86 一直未脱离这场竞争。
回到最初那个问题:为什么用 RISC 与 CISC 比较 x86 和 ARM CPU 是错误的?
当 Patterson 和 Ditzel 创造 RISC 和 CISC 时,他们打算阐明 CPU 设计的两种不同策略。四十年过去了,这些术语既模糊又清晰。RISC 和 CISC 并非毫无意义,但这两个术语的含义和适用性已变得高度语境化。
使用 RISC 与 CISC 来比较现代 x86 和 ARM CPU,其问题在于:它需要 3 个对 x86 和 ARM 比较重要的特定属性——制程节点、微架构和 ISA——将 3 个属性结婚在一起,然后才能声明 ARM 在 ISA 的基础上更胜一筹。「以 ISA 为中心」与「以实现为中心」是一种更好的理解方式,但前提是人们需要记得两者之间的关系。具体来说:
以 ISA 为中心的观点认为制造几何(manufacturing geometry)和微架构非常重要,并且促成了 x86 在 PC、服务器和 HPC 市场曾经的主导地位。这种观点认为,当制造能力和安装基础的优势被控制或取消时,RISC(以及 ARM CPU)通常会优于 x86 CPU。
以实现为中心的观点认为 ISA 确实很重要,但从发展历程的角度看,微架构和制程几何(process geometry)更重要。当前,英特尔正在努力缩小一些业内差距,AMD 在努力改进 Ryzen(尤其是在移动领域)。但从发展历程上看,这两家 x86 制造商都表现出具备与 RISC CPU 制造商有效竞争的能力。
考虑到 CPU 设计周期的现实情况,我们还需要几年的时间才能真正得出哪个观点更好的答案。今天的半导体市场与 20 年前的市场之间有一个区别:与英特尔在 1990 年代末和 2000 年代初所面临的大多数 RISC 制造商相比,台积电是一个更强大的代工竞争对手。英特尔的 7nm 团队不得不承受巨大的压力。
RISC 与 CISC 是理解两种不同类型 CPU 之间差异的起点,而不是今天如何比较的准确依据。
原文链接:https://www.extremetech.com/computing/323245-risc-vs-cisc-why-its-the-wrong-lens-to-compare-modern-x86-arm-cpus
2021 NeurIPS MeetUp China
受疫情影响,NeurIPS 2021依然选择了线上的形式举办。虽然这可以为大家节省一笔注册、机票、住宿开支,但不能线下参与这场一年一度的学术会议、与学术大咖近距离交流讨论还是有些遗憾。
今年,我们将在NeurIPS官方支持下,再次于 12 月份在北京举办线下NeurIPS MeetUp China,促进国内人工智能学术交流。
2021 NeurIPS MeetUp China将设置 Keynote、圆桌论坛、论文分享和 Poster 等环节,邀请顶级专家、论文作者与现场参会观众共同交流。
欢迎 AI 社区从业者们积极报名参与,同时我们也欢迎 NeurIPS 2021 论文作者们作为嘉宾参与论文分享与 Poster 展示。感兴趣的小伙伴点击「阅读原文」即可报名。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com